Ch10_텍스트 데이터 시각화 - WordCloud
학습목표
- 텍스트 데이터를 시각화하는 방법으로서 워드클라우드의 원리를 이해한다.
- 파이썬 WordCloud 라이브러리를 사용하여 텍스트 데이터를 시각화한다.
- 불용어 제거와 같은 기본적인 데이터 정리를 배운다.
- 마스크 이미지를 사용해 다양한 형태의 워드클라우드를 만든다.
- 워드클라우드를 통해 중요한 키워드와 패턴을 파악한다.
텍스트 데이터 시각화에서 워드클라우드(WordCloud)는 텍스트 데이터에서 중요한 키워드나 빈도수가 높은 단어를 효과적으로 시각화하는 데 유용하다. 이번 학습에서는 워드클라우드의 기본 개념과 함께 실제 구현 예시와 연습문제를 통해 활용 방법을 익힌다.
"단어에도 무게가 있다면, 어떤 단어는 가벼이 지나가고, 어떤 단어는 무겁게 남는다."
1. WordCloud의 개념
"단어에도 무게가 있다면, 어떤 단어는 가벼이 지나가고, 어떤 단어는 무겁게 남는다."
워드클라우드는 바로 이런 단어들의 '무게'를 시각적으로 표현하는 도구다. 텍스트 데이터에서 자주 등장하는 단어를 빈도수에 따라 강조해, 마치 단어들이 구름처럼 떠 있는 모습을 만들어낸다.
워드클라우드는 본래 '태그 클라우드(Tag Cloud)'라는 개념에서 시작되었다. 1990년대 웹 디자인에서 주로 사용되던 태그 클라우드는 웹페이지의 주제나 키워드를 시각적으로 강조하는 데 사용되었다. 시간이 지나면서 태그를 넘어 단순 텍스트 데이터를 시각화하는 워드클라우드로 진화했다. 지금은 데이터 분석과 시각화의 필수 도구로 자리 잡았다.
주요 특징:
- 단어의 빈도수에 따라 크기가 달라짐.
- 사용자가 원하는 모양(마스크 이미지)으로 시각화 가능.
- 색상과 배경을 커스터마이징하여 다양한 표현 가능.

워드 클라우드의 다양한 활용 사례
워드 클라우드는 단순한 시각화 도구를 넘어 텍스트 데이터에서 인사이트를 도출하고, 이를 다양한 분야에서 활용할 수 있는 강력한 도구로 자리 잡았다.

| 분야 | 적용 사례 | 장점 |
| 소셜 미디어 분석 | 트위터, 인스타그램, 페이스북 등에서 특정 해시태그, 키워드, 사용자 리뷰를 분석하여 특정 이벤트나 캠페인에 대한 사용자 반응 및 해시태그 빈도를 분석하고 트렌드를 파악합니다. | 특정 이슈에 대한 대중의 의견을 직관적으로 이해 가능 |
| 고객 리뷰 분석 | 제품 리뷰나 서비스 피드백에서 자주 언급되는 키워드를 추출하여 호텔 후기의 "청결", "위치", "친절" 또는 전자제품 리뷰의 "배터리", "화질", "디자인"과 같은 고객이 중요하게 생각하는 요소를 파악합니다. | 고객 만족도를 개선하기 위한 우선순위 도출 |
| 교육 및 학습 | 학생들의 에세이, 발표 자료, 또는 학술 논문의 주요 내용을 요약하여 강의 평가 데이터를 통해 수업에서 중요하게 여기는 주제를 파악하고 학술 자료의 주요 키워드를 도출합니다. | 텍스트 내용을 빠르게 요약하고 학습 자료를 직관적으로 표현 |
| 정치 및 선거 캠페인 분석 | 정치 연설문, 뉴스 기사, 유권자 의견 등을 분석하여 연설문에서 강조된 키워드와 선거 공약과 관련된 국민들의 관심사를 파악합니다. | 정치적 메시지와 공약에 대한 대중의 반응 이해 |
| 문학 및 예술 | 문학 작품, 노래 가사, 영화 대본 등에서 자주 사용되는 단어를 분석하여 셰익스피어 작품의 주요 단어를 시각화하거나 인기 노래 가사의 주제를 파악합니다. | 텍스트의 감성과 메시지를 독특한 방식으로 표현 |
| 공공 데이터 분석 | 공공 데이터 포털이나 정부 보고서에서 주요 주제를 시각화하여 지역별 관광지 리뷰를 분석하거나 의료 보고서에서 빈번하게 언급된 질병 키워드를 도출합니다. | 대중과 쉽게 소통할 수 있는 시각적 도구로 활용 가능 |
| 비즈니스 인텔리전스 | 시장 조사, 경쟁사 분석, 또는 내부 피드백 분석을 통해 경쟁사의 주요 제품 관련 키워드나 사내 설문조사 결과의 주요 단어를 추출합니다. | 전략적 의사결정을 위한 주요 데이터 제공 |
| 건강 데이터 분석 | 의료 설문, 환자 리뷰, 논문 키워드 분석을 통해 특정 질병에 대한 대중의 의견과 경험, 자주 언급되는 증상과 치료법을 분석합니다. | 건강 문제의 패턴을 시각적으로 이해 |
| 이벤트 및 브랜드 프로모션 | 이벤트 참석자의 후기나 브랜드 캠페인 반응을 분석하여 제품 출시 행사 피드백이나 브랜드와 연관된 긍정적 및 부정적 단어를 분석합니다. | 마케팅 전략 수립에 유용 |
한계
- 데이터 왜곡 가능성: 워드 클라우드는 단순히 단어의 빈도수에 기반하여 크기를 결정합니다. 이로 인해 문맥이나 단어 간의 관계를 반영하지 못해 데이터가 왜곡될 수 있습니다. 예를 들어, 정치 연설문에서 "국민"과 "대한민국" 같은 단어가 반복적으로 등장하면 중요해 보이지만, 이는 메시지의 실질적인 의미를 반영하지 않을 수 있습니다. 이 경우, 대중은 강조된 단어가 정책의 핵심이라고 오해할 가능성이 있습니다.
- 오해의 소지: 단어 크기와 빈도만으로는 데이터의 전체적인 맥락을 파악하기 어렵습니다. 예를 들어, 고객 리뷰에서 "가격"이라는 단어가 크다고 해서 반드시 긍정적인 평가를 의미하지는 않습니다. 높은 가격에 대한 불만이 주된 이유일 수도 있지만, 워드 클라우드는 이를 명확히 구분하지 못합니다. 따라서 단순한 시각화만으로는 데이터 해석이 잘못될 가능성이 있습니다.
- 세부 정보 전달의 한계: 워드 클라우드는 전체적인 트렌드를 보여주는 데는 효과적이지만, 데이터의 구체적인 상호 연관성을 나타내는 데는 부족합니다. 예를 들어, 의료 데이터를 분석할 때 "통증"이라는 단어가 빈번히 등장한다고 해서 특정 질병이나 원인을 바로 파악할 수 없습니다. 이러한 관계를 분석하려면 네트워크 그래프나 상관관계 분석 같은 추가적인 시각화가 필요합니다.
- 불용어 처리 문제: 불용어(stopwords)를 제대로 제거하지 않으면 분석 결과가 왜곡될 가능성이 있습니다. 예를 들어, 리뷰 데이터를 분석할 때 "그리고", "하지만" 같은 단어가 불용어로 처리되지 않으면, 실제로 중요한 키워드가 상대적으로 덜 부각되며 시각화의 신뢰성이 떨어질 수 있습니다.
이처럼 워드 클라우드는 직관적이고 효율적인 시각화 도구로 다양한 산업과 분야에서 활용될 수 있습니다. 하지만, 문맥이나 데이터의 본질을 간과할 가능성이 있는 한계가 있으므로, 다른 분석 도구와 보완적으로 사용하는 것이 중요합니다. 이러한 장단점을 이해하고 활용한다면 더 나은 데이터 분석과 시각화를 구현할 수 있습니다.
워드클라우드 생성에 사용되는 파이썬 라이브러리 요약
| 라이브러리 | 설명 | 기능 | 설치 |
| WordCloud | 텍스트 데이터를 기반으로 워드클라우드 생성 | 단어 크기 조정, 마스크 이미지 적용, 배경색 및 글꼴 커스터마이징 | pip install wordcloud |
| Matplotlib | 워드클라우드를 화면에 표시하고 시각화 | 워드클라우드 이미지 시각화, 그래프와 통합하여 표현 가능 | pip install matplotlib |
| Pillow (PIL) | 이미지 파일 처리 및 마스크 이미지 로드 | 마스크 이미지 불러오기, 사용자 지정 글꼴 설정 | pip install pillow |
| Numpy | 마스크 이미지를 숫자 배열로 변환 | 마스크 이미지를 픽셀 데이터 형태로 처리 | pip install numpy |
| Stopwords | 불용어를 제거하여 단어 필터링 | 의미 없는 단어(예: the, and)를 제거하여 중요한 단어만 포함 | WordCloud 내장 기능 |

위의 라이브러리와 기능을 조합하여 텍스트 데이터 시각화를 효과적으로 구현할 수 있다.
https://pypi.org/project/wordcloud/
https://pypi.org/project/wordcloud/
JavaScript is disabled in your browser. Please enable JavaScript to proceed. A required part of this site couldn’t load. This may be due to a browser extension, network issues, or browser settings. Please check your connection, disable any ad blockers, o
pypi.org
https://pillow.readthedocs.io/en/stable/
2. WordCloud 생성 과정
1) 텍스트 데이터 준비:
- 텍스트 데이터는 파일에서 불러오거나 직접 정의 가능.
text = "Python is an amazing language for data visualization and analysis."
- 데이터 전처리(불용어 제거, 소문자 변환, 토큰화 등)가 중요함.
- 주의점:
- 대소문자 변환 (소문자 통일)
- 구두점 제거
- 불용어 제거:
from wordcloud import STOPWORDS
stopwords = set(STOPWORDS)
stopwords.update(['Python', 'data'])
- STOPWORDS의 역할: 워드클라우드 라이브러리에서 제공하는 기본 불용어 리스트를 가져옵니다. 이 리스트에는 관사, 접속사와 같은 일반적으로 분석에 불필요한 단어가 포함되어 있습니다.
- stopwords.update()의 기능: 불용어 리스트에 사용자 정의 단어를 추가합니다. 위 예제에서는 'Python'과 'data'를 추가하여 이 단어들이 워드클라우드에서 제외되도록 설정했습니다.
2) 라이브러리 설치 및 사용:
- 필요한 파이썬 라이브러리: WordCloud, matplotlib, collections, numpy
pip install wordcloud matplotlib- WordCloud 주요 기능:
- 텍스트 데이터를 분석하여 단어의 빈도수에 따라 크기를 조정.
- 배경색, 글꼴, 색상, 크기 등을 커스터마이징 가능.
- 사용자 정의 마스크 이미지(모양)를 사용하여 다양한 형태의 워드클라우드를 생성.
- 불용어(stopwords)를 제거하여 필요 없는 단어를 필터링 가능.
3) 워드클라우드 생성 코드:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 텍스트 데이터 준비
text = """
데이터 시각화는 데이터를 이해하고 분석하는 데 필수적인 과정이다.
워드클라우드는 텍스트 데이터에서 중요한 단어를 시각적으로 표현한다.
파이썬에서 WordCloud 라이브러리를 사용하여 쉽게 생성할 수 있다.
"""
# 워드클라우드 객체 생성
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
# 워드클라우드 시각화
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
여기서 잠깐!
한글 처리
한글이 안 나와요!
파이썬의 워드클라우드 라이브러리는 기본적으로 영어 텍스트에 최적화되어 있습니다. 한글 텍스트를 처리하기 위해서는 추가적인 설정이 필요합니다. 특히 한글 글꼴(font)을 명시적으로 지정하지 않으면 글자가 깨지거나 출력되지 않을 수 있습니다. 아래는 한글 처리를 위한 단계별 코드와 설명입니다.
- 한글 글꼴 다운로드: 맑은 고딕, 나눔고딕, Noto Sans CJK와 같은 한글 지원 글꼴을 준비합니다.
아래 코드는 Google Colab 환경이나 리눅스 기반 시스템에서 NanumGothic 폰트를 설치하는 명령입니다. 이를 실행하면 시스템에 나눔고딕 폰트가 설치되며, 워드클라우드 생성 시 활용할 수 있습니다.
* 로컬 Windows/MacOS 환경에서는 나눔 폰트를 직접 다운로드하고 경로를 지정해야 합니다
# Install the NanumGothic font
!apt-get update && apt-get install -y fonts-nanum# Updated code
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 한글 텍스트 데이터 예시
text = """
안녕하세요. 파이썬으로 워드클라우드를 만들어 봅시다.
데이터 시각화는 매우 흥미롭고 강력한 도구입니다.
파이썬은 데이터 분석, 인공지능, 웹 개발 등에 널리 사용됩니다.
"""
# Update the font path to the correct location after installation
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
# 워드클라우드 생성
wordcloud = WordCloud(
font_path=font_path, # 한글 폰트 지정
width=640,
height=480, # 워드클라우드 세로 크기
background_color='white' # 배경색
).generate(text)
# 워드클라우드 출력
plt.figure(figsize=(10, 3))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 축 숨김
plt.show()4) 마스크 이미지 활용: 원하는 모양의 마스크 이미지를 적용해 시각화를 개선 가능.
- 마스크 이미지 형식
* 마스크 이미지는 흰색(255) 배경과 검은색(0) 도형의 형태로 되어 있어야 합니다.
* 다른 색상이 섞여 있거나 투명 채널(alpha)이 포함된 경우 문제가 발생할 수 있습니다. - 이미지를 열어 직접 확인하거나 아래 코드를 사용해 이미지 데이터를 출력합니다
from PIL import Image
import numpy as np
# 파일 경로가 정확한지 확인
try:
img = Image.open('/content/mask_image.png')
img.show() # 이미지를 열어서 확인
except FileNotFoundError:
print("The mask image file was not found. Check the file path.")- 이미지 차원 확인
mask = np.array(Image.open('/content/mask_image.png'))
print(mask.shape) # 이미지의 차원 출력
print(np.unique(mask)) # 이미지의 고유 값(픽셀 값) 확인- RGB를 흑백으로 변환
워드클라우드는 단일 채널로 작동하기 때문에 RGB 이미지를 흑백으로 변환해야 할 수도 있습니다.
즉, 픽셀 값이 [0, 255]로 되어 있지 않다면 이미지 전처리가 필요합니다.
mask = np.array(Image.open('/content/mask_image.png').convert('L')) # Convert to grayscale
mask = np.where(mask > 128, 255, 0) # Convert to binary (0 and 255)마스크 적용 워드클라우드 생성
import numpy as np
from PIL import Image
text = text = """
Hello, let's create a word cloud using Python.
Word clouds are useful and fun for data visualization.
Python is a popular tool for data analysis, artificial intelligence, and web development.
"""
# 마스크 이미지 로드
mask = np.array(Image.open('/content/mask_image.png'))
# 워드클라우드 생성 (마스크 적용)
wordcloud = WordCloud(mask=mask, background_color='white').generate(text)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
{kind=link}
import numpy as np
from PIL import Image
# 마스크 이미지 로드
mask = np.array(Image.open('mask_image.png'))
# 워드클라우드 생성 (마스크 적용)
wordcloud = WordCloud(mask=mask, background_color='white').generate(text)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()5) 시각화 및 저장
워드클라우드 또는 Matplotlib를 사용하여 결과를 시각화하고 필요에 따라 파일로 저장한다.
* 워드클라우드를 이미지 파일로 저장 : to_file()
- 'wordcloud_output.png': 저장될 파일명 (현재 디렉토리에 저장됨)
- 파일 형식은 확장자에 따라 결정됨 (예: .png, .jpg)
wordcloud.to_file('wordcloud_output.png')* matplotlib으로 저장 : plt.savefig()
import numpy as np
from PIL import Image
text = text = """
Hello, let's create a word cloud using Python.
Word clouds are useful and fun for data visualization.
Python is a popular tool for data analysis, artificial intelligence, and web development.
"""
# 마스크 이미지 로드
mask = np.array(Image.open('/content/mask_image.png'))
# 워드클라우드 생성 (마스크 적용)
wordcloud = WordCloud(mask=mask, background_color='white').generate(text)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('matplotlib_output.png')
plt.show()3.WordCloud 생성 시 주요 옵션
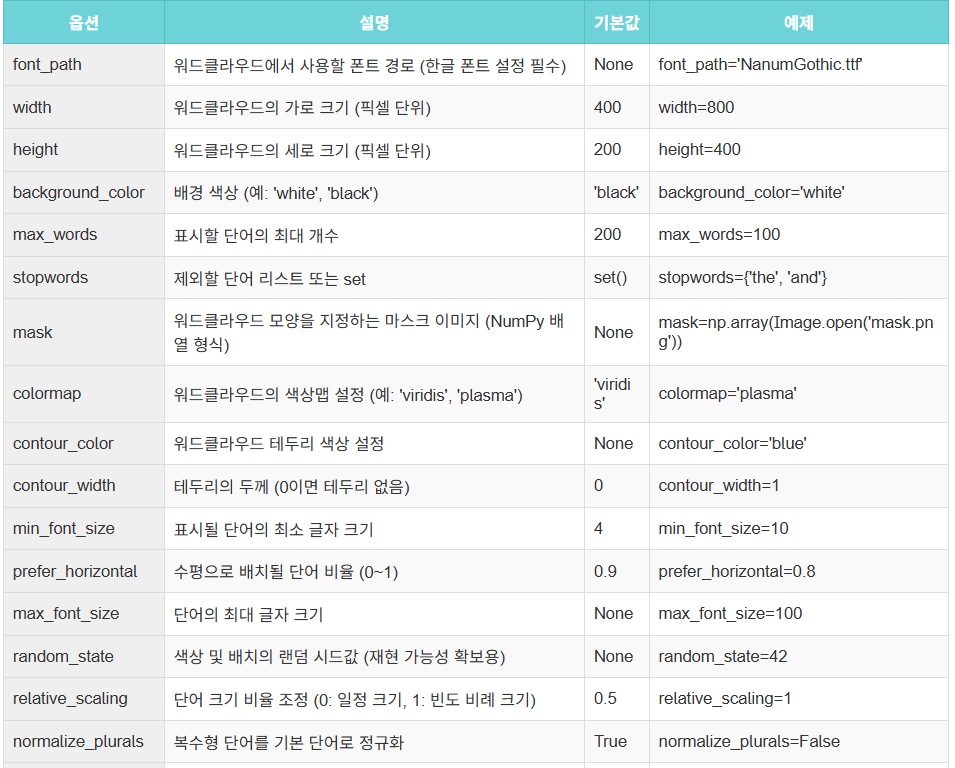
| 옵션 | 설명 | 기본값 | 예제 |
| font_path | 워드클라우드에서 사용할 폰트 경로 (한글 폰트 설정 필수) | None | font_path='NanumGothic.ttf' |
| width | 워드클라우드의 가로 크기 (픽셀 단위) | 400 | width=800 |
| height | 워드클라우드의 세로 크기 (픽셀 단위) | 200 | height=400 |
| background_color | 배경 색상 (예: 'white', 'black') | 'black' | background_color='white' |
| max_words | 표시할 단어의 최대 개수 | 200 | max_words=100 |
| stopwords | 제외할 단어 리스트 또는 set | set() | stopwords={'the', 'and'} |
| mask | 워드클라우드 모양을 지정하는 마스크 이미지 (NumPy 배열 형식) | None | mask=np.array(Image.open('mask.png')) |
| colormap | 워드클라우드의 색상맵 설정 (예: 'viridis', 'plasma') | 'viridis' | colormap='plasma' |
| contour_color | 워드클라우드 테두리 색상 설정 | None | contour_color='blue' |
| contour_width | 테두리의 두께 (0이면 테두리 없음) | 0 | contour_width=1 |
| min_font_size | 표시될 단어의 최소 글자 크기 | 4 | min_font_size=10 |
| prefer_horizontal | 수평으로 배치될 단어 비율 (0~1) | 0.9 | prefer_horizontal=0.8 |
| max_font_size | 단어의 최대 글자 크기 | None | max_font_size=100 |
| random_state | 색상 및 배치의 랜덤 시드값 (재현 가능성 확보용) | None | random_state=42 |
| relative_scaling | 단어 크기 비율 조정 (0: 일정 크기, 1: 빈도 비례 크기) | 0.5 | relative_scaling=1 |
| normalize_plurals | 복수형 단어를 기본 단어로 정규화 | True | normalize_plurals=False |
| include_numbers | 숫자를 포함할지 여부 | False | include_numbers=True |
3. 예제
1) 텍스트 파일 데이터 활용
with open('example_text.txt', 'r', encoding='utf-8') as file:
text = file.read()
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
2) 불용어 제거
stopwords = set(['데이터', '사용하여', '필수적인'])
wordcloud = WordCloud(
width=800, height=400,
background_color='white',
stopwords=stopwords
).generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
4.과제 및 실습
문제 1. 기본 WordCloud 생성하기
텍스트 데이터를 직접 작성하여 워드클라우드를 생성하고 출력하라.
# 텍스트 데이터
text = '''강아지는 매일 공원에서 뛰어논다. 공원은 강아지의 천국이다.
강아지는 공에서 놀고, 공원에서 뒹군다. 강아지가 가장 좋아하는 것은 공이다.
강아지는 공원에 가면 공을 쫓아 뛰고 또 뛴다.
공원에는 강아지 친구들이 많다. 강아지들은 서로 공을 나눠가며 논다.
강아지는 공과 함께 하는 하루가 행복하다. 공원은 강아지의 즐거운 놀이터다.
'''
# 워드클라우드 생성 및 시각화문제 2. 불용어 처리하기
다음 텍스트에서 불용어를 제거하고 워드클라우드를 생성하라.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = '''강아지는 매일 공원에서 뛰어논다. 공원은 강아지의 천국이다.
강아지는 공에서 놀고, 공원에서 뒹군다. 강아지가 가장 좋아하는 것은 공이다.
강아지는 공원에 가면 공을 쫓아 뛰고 또 뛴다.
공원에는 강아지 친구들이 많다. 강아지들은 서로 공을 나눠가며 논다.
강아지는 공과 함께 하는 하루가 행복하다. 공원은 강아지의 즐거운 놀이터다.
'''
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
stopwords = set(['강아지는'])여기서 잠깐!
한국어의 불용어 처리
워드클라우드에서 불용어 처리가 제대로 되지 않는 이유는 조사와 같은 문법 요소가 단어에 붙어 있기 때문입니다. WordCloud의 stopwords는 정확히 일치하는 단어만 제외하므로, 예를 들어 '강아지'는 제외되지만 '강아지는', '강아지와'는 여전히 워드클라우드에 포함될 수 있습니다.
조사가 붙은 단어를 제외하려면 텍스트를 전처리하여 조사를 제거해야 합니다. 이를 위해 형태소 분석 도구를 사용하는 것이 효과적입니다.
- Python에서는 konlpy와 같은 라이브러리를 사용하여 조사, 어미 등을 분리할 수 있습니다.
형태소 분석을 활용한 불용어 처리
pip install konlpyfrom wordcloud import WordCloud
from konlpy.tag import Okt
import matplotlib.pyplot as plt
# 한글 텍스트 데이터
text = '''강아지는 매일 공원에서 뛰어논다. 공원은 강아지의 천국이다.
강아지는 공에서 놀고, 공원에서 뒹군다. 강아지가 가장 좋아하는 것은 공이다.
강아지는 공원에 가면 공을 쫓아 뛰고 또 뛴다.
공원에는 강아지 친구들이 많다. 강아지들은 서로 공을 나눠가며 논다.
강아지는 공과 함께 하는 하루가 행복하다. 공원은 강아지의 즐거운 놀이터다.
'''
# 형태소 분석기 초기화
okt = Okt()
# 텍스트를 형태소 단위로 분리하여 명사만 추출
tokens = okt.nouns(text)
# 불용어 설정
stopwords = set(['강아지', '공', '공원'])
# 불용어 제거
filtered_text = ' '.join([word for word in tokens if word not in stopwords])
# 폰트 경로 설정 (Linux 기준)
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
# 워드클라우드 생성
wordcloud = WordCloud(
font_path=font_path,
width=640,
height=480,
background_color='white'
).generate(filtered_text)
# 워드클라우드 시각화
plt.figure(figsize=(10, 3))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 축 숨기기
plt.show()문제 3. 마스크 이미지 활용하기
로컬에 저장된 마스크 이미지(mask_star.png)를 사용하여 워드클라우드를 생성하라.
{kind=link}
마스크 이미지 준비:
- 마스크 이미지는 PNG 또는 JPEG 형식의 흑백 이미지여야 함.
- 배경은 흰색, 모양은 검은색으로 설정.
- 이미지 예: 서울 지도, 경복궁 실루엣, 랜드마크 사진.

문제 4. 위키피디아 워드 클라우드
- wikipedia 라이브러리를 사용하여 "Artificial Intelligence" 제목의 위키피디아 페이지 내용을 기반으로 워드클라우드를 생성
1. 필요한 라이브러리 설치
pip install wikipedia wordcloud matplotlib2. 코드 작성
import wikipedia
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as pltStep 1: 위키피디아 페이지 가져오기
wiki = wikipedia.page('Artificial intelligence')
text = wiki.contentStep 2: 불용어 설정
# 불용어(stopwords) 정의
# - 기본 STOPWORDS에 추가로 제외할 단어를 정의
stopwords = set(STOPWORDS) # 기본 제공되는 불용어 리스트를 불러옴
stopwords.update(['one', 'using', 'first', 'two', 'use', 'will']) # 추가 불용어를 업데이트Step3: 워드클라우드 생성
# 워드클라우드 생성
wordcloud = WordCloud(
width=800,
height=400,
background_color='white', # 배경색 흰색으로 설정
stopwords=stopwords # 정의한 불용어를 적용
).generate(text) # 텍스트 데이터를 기반으로 워드클라우드 생성Step4 : 시각화와 파일 저장
# 워드클라우드 시각화와 파일 저장
plt.figure(figsize=(10, 5)) # 출력될 워드클라우드 크기 설정 (인치 단위)
plt.imshow(wordcloud, interpolation="bilinear") # 워드클라우드 이미지 출력 (bilinear 보간법 사용)
plt.axis('off')
plt.show()
wordcloud.to_file('wc_AI.png')Plotly를 활용한 인터랙티브 워드클라우드
Plotly는 인터랙티브 데이터 시각화를 지원하는 강력한 라이브러리입니다. 이를 활용해 워드클라우드를 생성하면 사용자가 마우스 오버 및 확대/축소 등의 동작을 통해 데이터를 동적으로 탐색할 수 있습니다.
Plotly 자체적으로 워드클라우드 기능을 제공하지는 않지만, Scatter 차트를 활용해 유사한 결과를 구현할 수 있습니다.
주요 특징:
- 단어를 클릭하면 해당 단어와 관련된 리뷰를 표시.
- 워드클라우드와 텍스트 데이터가 연결된 인터랙티브 대화형 UI 제공.
Data Apps for Production | Plotly
Discover data applications for production with Plotly Dash. Put data and AI into action with scalable, interactive data apps for your organization.
plotly.com
실습: 간단한 예제
종합예제 : 관광지 리뷰를 Plotly로 시각화 해 보자.
import pandas as pd
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
# 1. 샘플 데이터 준비
data = {
"review": [
"서울의 경복궁은 정말 아름다워요!",
"남산타워에서 본 야경은 잊을 수 없어요.",
"명동에서 쇼핑하는 게 가장 즐거웠습니다.",
"북촌 한옥마을은 한국의 전통을 느낄 수 있어요.",
"광화문은 역사적인 느낌이 가득합니다.",
"한강에서 자전거를 타며 힐링했어요.",
]
}
df = pd.DataFrame(data)
# 2. 텍스트 데이터 전처리
text = " ".join(df['review']) # 모든 리뷰 텍스트 결합
stopwords = set(STOPWORDS)
stopwords.update(['서울', '정말', '게', '는', '에서', '가장', '수', '느낄']) # 불용어 추가
# 3. 워드클라우드 생성 및 단어 빈도 추출
wordcloud = WordCloud(stopwords=stopwords, background_color="white", width=800, height=400).generate(text)
# 단어 빈도 추출
word_freq = wordcloud.words_
# 4. 데이터 프레임 생성 (단어와 빈도)
word_freq_df = pd.DataFrame(list(word_freq.items()), columns=["word", "frequency"])
# 5. Plotly를 사용한 인터랙티브 워드클라우드
fig = px.scatter(
word_freq_df,
x="frequency",
y="word",
size="frequency",
color="frequency",
hover_name="word",
title="Interactive WordCloud",
labels={"frequency": "Word Frequency", "word": "Word"}
)
fig.update_traces(marker=dict(opacity=0.7, sizemode="area", line=dict(width=2, color="DarkSlateGrey")))
# 6. 클릭 이벤트 추가 (리뷰 출력)
def show_reviews(click_data):
if click_data:
clicked_word = click_data["points"][0]["hovertext"]
reviews_containing_word = df[df['review'].str.contains(clicked_word, na=False)]
print(f"단어 '{clicked_word}' 관련 리뷰:")
for review in reviews_containing_word['review']:
print("-", review)
fig.show()
# 7. 사용자 입력 시 리뷰 표시
# 이벤트 예: 사용자가 단어를 클릭하면 show_reviews 함수를 호출하여 관련 리뷰를 출력
click_data = {"points": [{"hovertext": "경복궁"}]} # 샘플 클릭 데이터
show_reviews(click_data)- 워드클라우드 데이터 생성:
- WordCloud로 단어와 빈도 데이터를 추출.
- Plotly의 scatter를 활용해 시각화.
- 클릭 이벤트:
- 사용자가 단어를 클릭하면 관련 리뷰를 필터링하여 콘솔에 출력.
- 실제 서비스에서는 Plotly Dash를 활용해 웹 기반으로 구현 가능.
- 확장 가능성:
- 클릭 시 별도 창에 리뷰를 보여주거나, 다른 시각화를 연동할 수 있다.
- 여러 데이터를 통합하여 다양한 분석이 가능하다.