Ch12_텍스트 분류 - 머신러닝
학습목표
- 텍스트 분류의 기본 개념 이해
- 텍스트 데이터를 전처리하고 머신러닝 모델에 적용하는 방법 학습
- 간단한 텍스트 분류 모델을 직접 구현
"기계도 편지를 읽을 수 있을까?"

어느 날, 여러분의 이메일함에 "당첨! 무료 여행 쿠폰!"이라는 제목의 메시지가 도착했다고 상상해 보자. 두근거리는 마음으로 열어보았더니, 역시나 흔한 스팸 메시지다. 그런데 이상하지 않은가? 우리는 제목만 보고도 스팸인지 아닌지 직감적으로 알 수 있다. 그렇다면 컴퓨터도 우리처럼 이런 메시지를 "읽고" 판단할 수 있을까?
사실 컴퓨터는 우리가 상상하는 것보다 더 똑똑하다. 문자, 단어, 문장을 단순한 데이터로 보고 규칙을 배우기 때문이다. 이 과정에서 사용되는 기술이 바로 머신러닝(Machine Learning)이다. 머신러닝은 컴퓨터가 데이터를 통해 스스로 학습하고, 미래의 데이터를 예측하거나 분류하는 방법이다. 텍스트 분류는 그중에서도 우리가 매일 사용하는 언어를 이해하고 처리하는 대표적인 예로, 이메일 스팸 필터, 뉴스 카테고리 분류, 영화 리뷰 감성 분석 등 다양한 분야에서 활용된다.
오늘 이 강의에서는 텍스트 데이터를 이용해 컴퓨터가 "이 메시지는 스팸이다" 또는 "이 리뷰는 긍정적이다"라고 스스로 판단하도록 만드는 과정을 탐구할 것이다. 여러분도 이런 기계의 판단 과정을 이해하고 직접 만들어볼 수 있다는 점에서 흥미롭지 않은가?
1. 텍스트 분류 개요
1.1 텍스트 분류란?
텍스트 분류는 특정한 문장이나 문서를 미리 정의된 카테고리로 자동 분류하는 작업이다. 예를 들어:
- 이메일 스팸 필터링: "이 메시지가 스팸인가 아닌가?"
- 뉴스 분류: "이 뉴스는 스포츠, 정치, 과학 중 어떤 카테고리에 속하는가?"
- 감성 분석: "이 영화 리뷰는 긍정적인가 부정적인가?"
이러한 작업은 사람이 모든 문서를 직접 분류하는 것보다 훨씬 빠르고 정확하게 처리할 수 있다. 하지만 컴퓨터가 인간처럼 문장을 이해하는 것은 아니다. 대신, 컴퓨터는 텍스트를 숫자로 변환하여 처리한다.
1.2 텍스트 데이터를 컴퓨터가 이해하도록 만드는 방법
문장을 컴퓨터가 이해하려면 어떻게 해야 할까? 컴퓨터는 단어 자체를 이해하지 못하지만, 이를 숫자로 변환해 수학적 패턴을 학습할 수 있다. 이를 위해 텍스트 데이터를 처리하는 몇 가지 단계가 필요하다.
1) 텍스트 전처리
텍스트를 숫자로 변환하기 전에 데이터를 정리하는 과정이다.
- 클렌징(Cleansing): 텍스트에서 분석에 방해가 되는 불필요한 문자나 기호를 제거합니다. 예를 들어, HTML 태그나 특수 문자를 삭제합니다.
- 토큰화: 문장을 단어 또는 구로 나눈다. 예: "I love programming" → ["I", "love", "programming"]
- 불용어 제거: "the", "and", "is"처럼 의미가 적은 단어를 제거한다.
- 어간 추출 및 표제어 추출: 단어의 기본 형태로 변환한다. 예: "running", "runs", "ran" → "run"
2) 피처 벡터화(Feature Vectorization)
텍스트 데이터를 숫자로 변환하는 단계이다.
- Bag of Words (BoW): 텍스트를 단어의 빈도수로 표현하는 기법입니다. 각 단어의 등장 횟수를 세어 벡터로 변환합니다.
- TF-IDF(Term Frequency-Inverse Document Frequency): 단어의 중요도를 계산하여 가중치를 부여하는 방법입니다. 자주 등장하지만 중요하지 않은 단어에는 낮은 가중치를, 드물게 등장하지만 중요한 단어에는 높은 가중치를 부여합니다.
1.3 머신러닝 (Machine Learning) 알고리즘으로 텍스트 분류하기
머신러닝은 "경험에서 배우는 컴퓨터"라고 할 수 있다.
머신러닝은 "컴퓨터가 경험에서 배우는 기술"이라고 할 수 있다. 정확히 말하면, 머신러닝(Machine Learning)은 컴퓨터가 데이터를 통해 스스로 학습하고, 특정한 작업을 수행하거나 문제를 해결할 수 있도록 만드는 기술이다. 기존의 전통적인 프로그래밍에서는 사람이 모든 규칙을 하나하나 작성해야 했다. 반면, 머신러닝은 데이터를 기반으로 컴퓨터가 규칙과 패턴을 스스로 찾아내는 방식으로 작동한다.
예를 들어, 사람이 고양이 사진을 보면 쉽게 고양이인지 아닌지 구별할 수 있다. 하지만 컴퓨터는 "고양이란 무엇인가?"를 알지 못한다. 머신러닝을 활용하면, 컴퓨터에 고양이 사진을 여러 장 보여주고 "이건 고양이다"라고 알려주는 과정을 통해 고양이의 특징(예: 귀 모양, 꼬리, 얼굴 구조 등)을 학습시킬 수 있다. 이후 새로운 사진을 보여주었을 때, 컴퓨터는 학습한 내용을 바탕으로 "이 사진에 고양이가 있는지"를 판단할 수 있게 된다.
머신러닝은 학습 방식에 따라 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning)의 세 가지로 나뉜다.
- 지도학습(Supervised Learning)은 입력 데이터와 정답(레이블)이 함께 제공되는 방식이다. 컴퓨터는 정답을 학습하여 새로운 데이터를 예측할 수 있다. 예를 들어, 이메일에서 스팸 여부를 분류하거나 집값을 예측하는 작업에 사용된다. 주요 알고리즘으로는 로지스틱 회귀, 나이브 베이즈, 서포트 벡터 머신(SVM), 랜덤 포레스트 등이 있다.
- 비지도학습(Unsupervised Learning)은 정답(레이블)이 없는 데이터에서 패턴이나 구조를 학습하는 방식이다. 데이터를 군집화하거나 숨겨진 특징을 발견하는 데 주로 활용된다. 예를 들어, 고객을 구매 패턴에 따라 그룹으로 나누거나 문서의 주제를 분석하는 작업에 사용된다. 자주 사용되는 알고리즘으로는 K-평균(K-Means), 주성분 분석(PCA), DBSCAN 등이 있다.
- 강화학습(Reinforcement Learning)은 컴퓨터가 환경과 상호작용하며 학습하는 방식이다. 특정 행동의 결과로 주어진 보상(Reward) 또는 벌점(Penalty)을 통해 점진적으로 학습하며 최적의 행동 전략(Policy)을 찾아간다. 대표적인 예로는 체스와 같은 게임 AI, 로봇의 장애물 회피 학습 등이 있다.
이 세 가지 학습 방식은 문제의 종류와 데이터 형태에 따라 적절히 선택되어 사용된다. 각각의 방식은 서로 다른 상황에서 효과적으로 활용되며, 텍스트 분류 문제에서도 머신러닝의 이러한 개념들이 중요한 역할을 한다.
대표적인 텍스트 분류 알고리즘
텍스트 분류에서 머신러닝 모델은 전처리된 데이터를 학습하고, 새로운 데이터를 분류할 수 있도록 돕는다. 텍스트 분류에서 자주 사용하는 알고리즘은 다음과 같다.
1. 나이브 베이즈 (Naive Bayes):
- 나이브 베이즈는 확률을 기반으로 한 머신러닝 알고리즘이다.
- 데이터를 보고, 특정 카테고리에 속할 가능성이 가장 높은 것을 선택한다.
어떻게 작동하나?
- 예를 들어, "Win a free trip!"이라는 이메일이 있을 때, 나이브 베이즈는 "Win", "free", "trip"과 같은 단어가 스팸 이메일에서 얼마나 자주 나타났는지를 계산한다.
- 그런 다음, 이 이메일이 스팸일 가능성과 비스팸일 가능성을 비교하여 더 높은 확률로 결론을 내린다.
- 장점: 간단하고 빠르며, 적은 데이터로도 잘 작동한다.
- 단점: 단어 간의 관계(문맥)를 고려하지 못한다. 예: "Not bad"와 "Very bad"를 같은 부정적으로 판단할 수 있다.
2. 로지스틱 회귀 (Logistic Regression):
- 이름은 회귀이지만, 실제로는 이진 분류 문제를 해결하는 데 사용된다.
- 특정 데이터가 한 카테고리에 속할 확률을 예측한다.
어떻게 작동하나?
- 로지스틱 회귀는 데이터를 보고, 그 데이터가 특정 카테고리에 속할 가능성을 0에서 1 사이의 값으로 계산한다.
- 예를 들어, "I love this product"이라는 문장이 긍정적인지 부정적인지를 분류할 때, "긍정적일 확률이 0.85"라면 긍정적으로 판단한다.
- 장점: 해석이 쉽고, 분류 문제에 효과적이다. 텍스트 분류, 감성 분석, 이메일 스팸 필터링 등에 자주 사용된다.
- 단점: 복잡한 데이터에는 적합하지 않을 수 있다.
3. 서포트 벡터 머신 (Support Vector Machine, SVM):
- 데이터를 두 카테고리로 나누는 가장 최적의 경계선을 찾는 알고리즘이다.
- 데이터를 분류하는 선(또는 경계선)을 그어, 분류 결과를 개선한다.
어떻게 작동하나?
- 예를 들어, "Win a free trip!"이라는 문장을 SVM에 입력하면, SVM은 "스팸"과 "비스팸"의 중간 경계선을 찾는다.
- 새로운 문장이 들어오면 그 문장이 경계선의 어느 쪽에 속하는지를 보고 분류한다.
- 장점: 복잡한 데이터에도 잘 작동하며, 높은 정확도를 제공한다. 소량의 데이터로도 좋은 결과를 얻을 수 있다.
- 단점: 데이터가 많거나 크면 계산이 느려질 수 있다.
1. 4. 모델 평가 지표
머신러닝 모델의 성능을 측정하기 위해 다양한 지표를 사용한다.
다음은 머신러닝 모델의 성능 평가 지표를 초보자가 이해하기 쉽도록 테이블로 정리한 내용이다:
| 평가지표 | 정의 | 수식 | 활용 |
| 정확도 (Accuracy) | 전체 데이터 중 올바르게 분류된 데이터의 비율 |  |
- 모델의 전반적인 성능을 측정 - 데이터의 클래스 비율이 균형일 때 적합 |
| 정밀도 (Precision) | 모델이 양성(Positive)으로 예측한 데이터 중 실제로 양성인 데이터의 비율 | 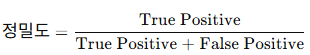 |
- 잘못된 양성 예측(오탐지)을 줄이는 데 초점 - 중요: 스팸 필터링에서 "정확한 스팸 탐지" |
| 재현율 (Recall) | 실제 양성(Positive) 데이터 중 모델이 올바르게 양성으로 예측한 비율 | 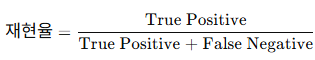 |
- 놓친 양성 데이터(미탐지)를 줄이는 데 초점 - 중요: 질병 진단에서 "모든 환자를 탐지하는 능력" |
| F1 점수 (F1 Score) | 정밀도와 재현율의 조화 평균 |  |
- 정밀도와 재현율 간의 균형을 평가 - 중요: 데이터의 클래스 비율이 불균형일 때 유용 |
초보자를 위한 머신러닝 이해 요령
머신러닝은 처음에는 복잡하게 느껴질 수 있다. 하지만 이를 텍스트 분류와 같은 실생활의 문제에 적용하면 더 쉽게 이해할 수 있다. 핵심은 데이터를 준비하고, 텍스트를 숫자로 변환하며, 머신러닝 알고리즘을 사용해 학습한 후, 새로운 데이터를 예측하는 것이다.예제와 실습으로 이러한 과정을 경험하면 머신러닝이 훨씬 친숙하게 다가올 것이다!

2. "머신러닝과 함께하는 첫걸음: 텍스트 분류 실습하기"
2.1 환경 설정
- 필수 라이브러리 설치
!pip install scikit-learn nltk- 데이터 준비 : 간단한 이메일 텍스트 데이터를 생성하거나 제공된 텍스트 파일을 업로드.
2.2 텍스트 데이터 전처리
- 1) 샘플 데이터 생성
# 샘플 이메일 데이터
emails = [
"Congratulations! You have won a free ticket.",
"Hello, your meeting is scheduled for tomorrow.",
"Win a free coupon now!",
"Your invoice is due next week.",
"Claim your free prize today!"
]
labels = [1, 0, 1, 0, 1] # 1: 스팸, 0: 비스팸- 2) 텍스트 전처리
from sklearn.feature_extraction.text import CountVectorizer
# 텍스트 데이터를 벡터화
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(emails)
print(vectorizer.get_feature_names_out()) # 단어 리스트 확인
print(X.toarray()) # 벡터화된 데이터 출력2.3 머신러닝 모델 학습 및 예측
- 데이터 분리
from sklearn.model_selection import train_test_split
# 훈련 데이터와 테스트 데이터로 분리
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)- 나이브 베이즈 모델 학습
from sklearn.naive_bayes import MultinomialNB
# 모델 학습
model = MultinomialNB()
model.fit(X_train, y_train)- 예측 및 평가
from sklearn.metrics import classification_report
# 테스트 데이터 예측
y_pred = model.predict(X_test)
print("예측 결과:", y_pred)
# 성능 평가
print(classification_report(y_test, y_pred))2.4. 결과 해석
결과 확인: 예측된 결과와 실제 레이블 비교
- 예측된 결과(y_pred): 모델이 테스트 데이터에 대해 예측한 결과.
- 실제 레이블(y_test): 테스트 데이터의 실제 정답.
예측 결과(y_pred): [1, 0] # 모델이 예측한 값
실제 레이블(y_test): [1, 0] # 실제 데이터 정답- 모델이 예측한 결과가 실제 레이블과 일치하는 경우, 올바른 예측으로 간주.
- 일치하지 않는 경우, 모델이 틀린 예측을 한 것이다.
쉬운 예시:
- "Win a free coupon now!" → 모델: 스팸(1), 실제: 스팸(1) → 올바른 예측
- "Your invoice is due next week." → 모델: 비스팸(0), 실제: 비스팸(0) → 올바른 예측
학습 내용을 실생활에 적용 해 보자.
- 고객 리뷰, 트윗, 영화 평점 등을 분석해 긍정적/부정적 감정을 분류.
- 채팅봇 개선: 고객 문의 유형에 따라 답변 자동화.
- 전자상거래: 제품 리뷰를 분석해 고객 만족도 조사
- 의료 데이터 분석 : 설명: 의사가 작성한 환자 기록을 분석해 특정 질병 카테고리로 분류.
과제 1. "국민 민원 데이터를 카테고리별로 분류하기" 😊
- 민원 데이터를 분석하여 교통, 환경, 복지 등 카테고리로 자동 분류
- 민원 처리 프로세스를 효율화하는 데 도움 제공
# 필요한 라이브러리 설치
!pip install scikit-learn pandas데이터 준비: 민원 제목과 내용을 텍스트 데이터로 사용하고, 카테고리를 레이블로 사용.
import pandas as pd
# 샘플 민원 데이터 생성
data = {
"민원 제목": [
"도로에 가로등이 고장났어요",
"쓰레기 무단 투기 신고합니다",
"노인 복지 혜택을 늘려주세요",
"횡단보도에 신호등이 고장났어요",
"공원에 쓰레기가 많아요"
],
"민원 내용": [
"우리 동네 가로등이 꺼져있어 밤에 너무 어두워요.",
"아파트 뒤편에 쓰레기를 아무데나 버리는 사람들이 많습니다.",
"노인들이 받을 수 있는 복지 혜택이 부족합니다.",
"횡단보도 신호등이 작동하지 않아 사고 위험이 있습니다.",
"공원 곳곳에 쓰레기가 방치되어 있어 불편합니다."
],
"카테고리": ["교통", "환경", "복지", "교통", "환경"]
}
df = pd.DataFrame(data)
print(df)벡터화: 텍스트 데이터를 숫자로 변환하여 머신러닝 모델에 입력 가능하게 만듦.
from sklearn.feature_extraction.text import CountVectorizer
# 민원 제목과 내용을 합쳐서 사용
df["텍스트"] = df["민원 제목"] + " " + df["민원 내용"]
# 텍스트 데이터를 벡터화
vectorizer = CountVectorizer(stop_words="english")
X = vectorizer.fit_transform(df["텍스트"])
# 카테고리를 숫자로 변환
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y = encoder.fit_transform(df["카테고리"])
# 벡터화된 데이터와 레이블 확인
print("단어 벡터화 결과:")
print(X.toarray())
print("레이블:")
print(y)모델 학습: 나이브 베이즈 모델로 훈련 데이터 학습.
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 훈련 데이터와 테스트 데이터로 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 나이브 베이즈 모델 학습
model = MultinomialNB()
model.fit(X_train, y_train)성능 평가: 정밀도, 재현율, F1 점수를 통해 모델 평가.
from sklearn.metrics import classification_report
# 테스트 데이터 예측
y_pred = model.predict(X_test)
# 결과 평가
print("모델 성능 평가:")
print(classification_report(y_test, y_pred, target_names=encoder.classes_))새로운 데이터 예측: 입력된 민원의 텍스트를 분류하여 카테고리를 자동으로 예측
# 새로운 민원 데이터
new_data = ["동네 신호등이 고장났어요.", "공원에 쓰레기가 너무 많습니다."]
new_vector = vectorizer.transform(new_data)
# 예측
new_pred = model.predict(new_vector)
predicted_categories = encoder.inverse_transform(new_pred)
# 결과 출력
for text, category in zip(new_data, predicted_categories):
print(f"민원: '{text}' -> 예측된 카테고리: '{category}'")코드 실행 결과 예시
모델 성능 평가:
precision recall f1-score support
교통 1.00 1.00 1.00 1
복지 1.00 1.00 1.00 1
환경 1.00 1.00 1.00 1민원: '동네 신호등이 고장났어요.' -> 예측된 카테고리: '교통'
민원: '공원에 쓰레기가 너무 많습니다.' -> 예측된 카테고리: '환경'핵심 키워드
- 텍스트 전처리
- 토큰화(Tokenization)
- 불용어 제거(Stopword Removal)
- 어간 추출(Stemming) / 표제어 추출(Lemmatization)
- 정규화(Text Normalization)
- 피처 추출
- Bag of Words (BoW)
- TF-IDF (Term Frequency-Inverse Document Frequency)
- Word Embedding (Word2Vec, GloVe, FastText)
- 알고리즘
- 나이브 베이즈(Naive Bayes)
- 로지스틱 회귀(Logistic Regression)
- 서포트 벡터 머신(SVM)
- 딥러닝 모델(예: RNN, LSTM, Transformer)
- 모델 평가
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현율(Recall)
- F1 점수(F1 Score)
- 혼동 행렬(Confusion Matrix)
- 머신러닝
- 지도학습(Supervised Learning)
- 비지도학습(Unsupervised Learning)
- 강화학습(Reinforcement Learning)
- 훈련 데이터(Training Data)
- 테스트 데이터(Test Data)
- 교차 검증(Cross-Validation)
- 데이터 정규화(Data Normalization)
- 회귀 분석(Linear Regression, Logistic Regression)
- 분류(Classification)
- 클러스터링(Clustering)