
티스토리 뷰
1. 데이터 준비
data > dataset > abalone
2. 데이터 불러오기

3. 데이터 살펴보기
http://archive.ics.uci.edu/ml/datasets/Abalone
UCI Machine Learning Repository: Abalone Data Set
Data Set Characteristics: Multivariate Number of Instances: 4177 Area: Life Attribute Characteristics: Categorical, Integer, Real Number of Attributes: 8 Date Donated 1995-12-01 Associated Tasks: Classification Missing Values? No Number of Web Hits: 12
archive.ics.uci.edu
4. 데이터시각화하기
- 산점도

5. 데이터 전처리하기
- Transform > Select Colums 추가

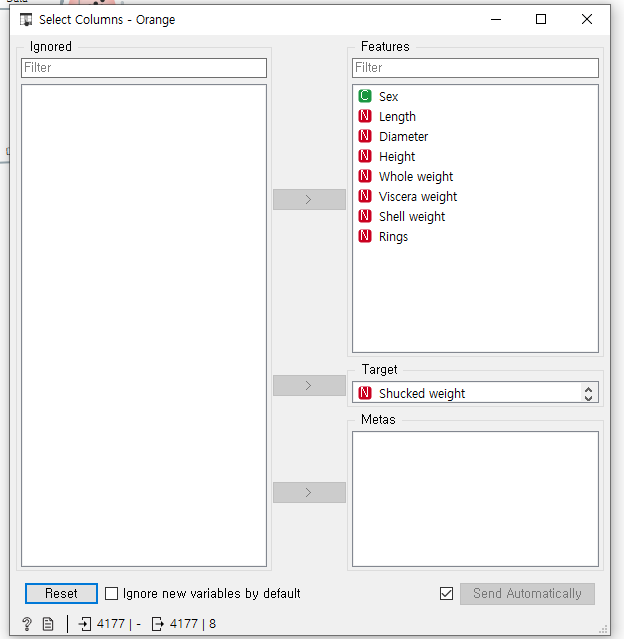
- 새로운 datatable 연결
- Transform > Select Colums 방법
1. 요소에서 항목 선택 후 ignored > 다시 Target 으로 선택 이동
- features : 변수
- target : 예측하고자 하는 결과가 되는 속성
- Metas : 사용되지는 않지만, 참고용
- Ignored : 무시할 데이터
# 데이터 종류
- C ; 범주형, 논리형
- N : 수치형
- S : text/문자
-T : dateTime/날짜
6. 학습 모델 선택하기
1. 훈련데이터(train)와 테스트(test)데이터 나누기
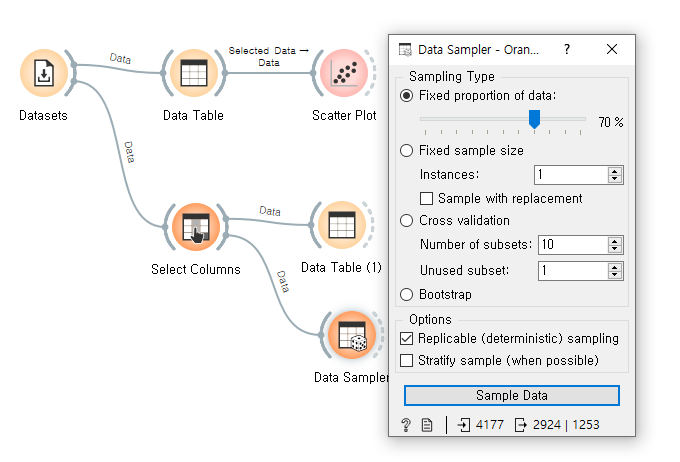
2. 모델 선택
- model > linear Regression 선형회귀모델 - 연속적인 값의 예측하는 모델
선형회귀 모델은 지도 학습 알고리즘으로 주로 수치 예측 문제에 사용
립면수 (인풋 변수, X)를 이용해서 숫자인 종속 변수(아웃풋 변수, Y)를 예측하는 모델
직선의 방정식
- Y = aX + b
- Y = 기울기 * X + Y절편
https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%ED%9A%8C%EA%B7%80
3. 학습
- overfitting : 데이터를 과하게 학습하면 과적합
-
7. 모델의 성능 검사 (Evaluate 위젯)
- 만든 모델의 학습이 얼마나 예측을 잘하는지 평가 해 보자.
학습결과 확인



성능결과 확인

평가지표
- MSE : mean Squared Error - 0에 가까울수록 예측값과 실제값의 차이가 없으므로 성능이 우수하다.
- RMSE : Root Mean Squared Error - 0에 가까울수록 성능이 우수
- MAE : Mean Absolute Error - 0에 가까울수록 성능이 우수
- R2 : 결정계수 - 1에 가까울수록 성능이 우수
- Total
- Today
- Yesterday